Let’s say one of your adversaries is known for using a given malware family, custom or off-the shelf. Even if the coverage is biased and limited, samples on VirusTotal (VT) are the low-hanging fruits that keep on giving.
At $WORK, we are lucky to have access to the Virus Total feeds/file API. This API endpoint is the firehose of VirusTotal: it allows downloading each sample submitted to VT in pseudo-real-time. The feed is unfiltered (we are not talking about VT’s LiveHunt feature) so the volume is HUGE.
We set the crazy objective to extract and push IOC in real-time for a given malware family submitted to VirusTotal. For this blog post, as an example, we will focus on Cobalt Strike.
The steps are:

- Download each sample submitted
- Apply Yara rules matching the malware families we are interested in
- Automatically extract C2 configuration
- Disseminate IOC
Initially, we used our on-premises infrastructure with 2-3 servers. Quickly, the operational maintenance killed us:
- Our Celery cluster was regularly KO.
- Everything had to be very carefully tuned (memory limits, batch size, timeout, retries), we were constantly juggling with the balance between completeness, stability, and speed.
- Adding an under-performing Yara rule could break the platform.
- It was also not a good use of our computing resources as VT’s activity is not evenly spread across the day: our servers were under-used most of the day while overloaded during the peaks.
Going Serverless 🔗
Taking a step back, it jumped out at us that this was a textbook example for a Serverless architecture. It was easy to refactor our on-prem code into self-contained functions and glue them together with Amazon SQS:
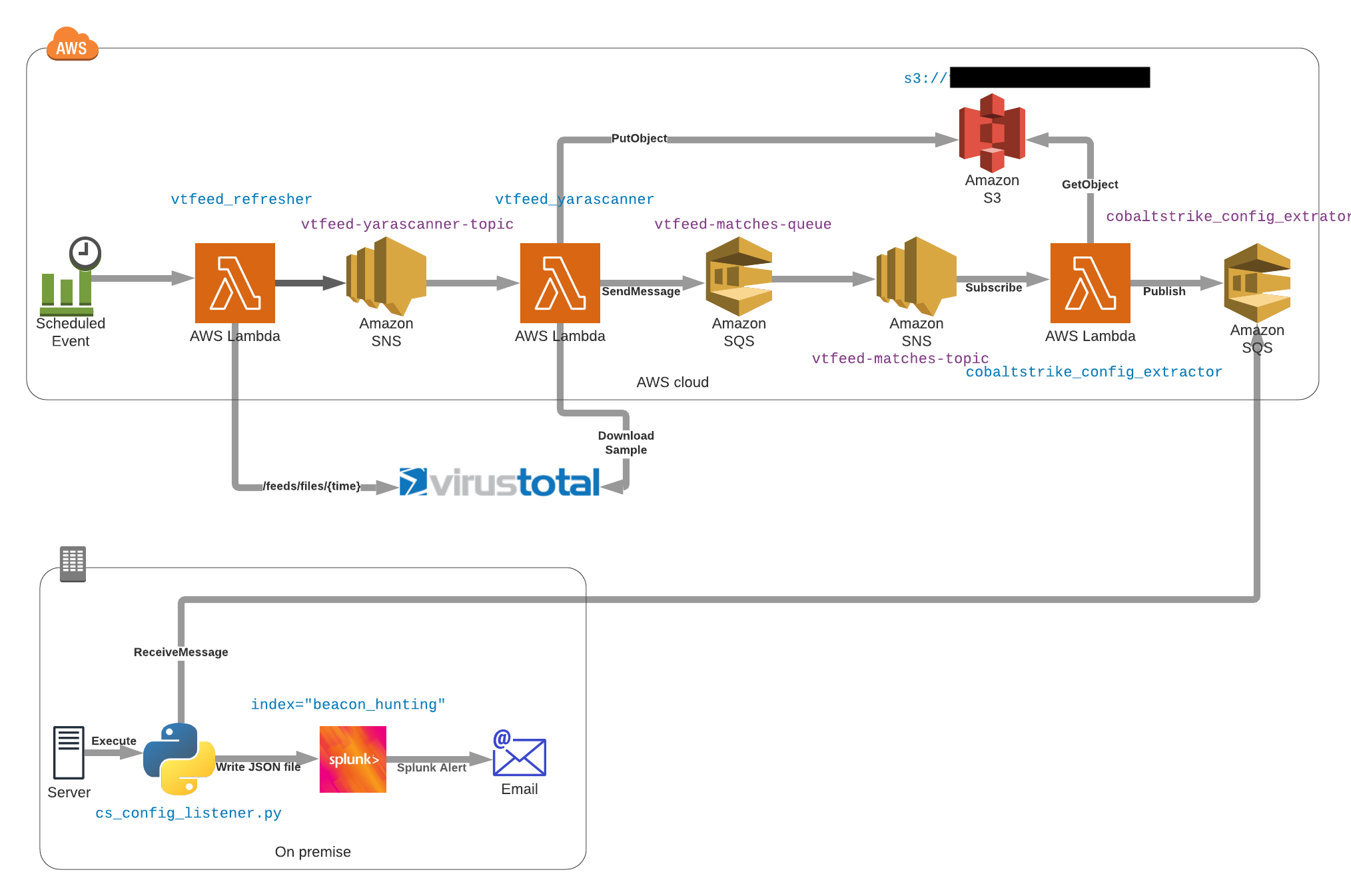
The platform has been running smoothly for 18 months, and from an operational point of view, we love it:
- The scalability of the platform allowed us to not mind anymore about the performance of each rule: we can add our Yara rules quite freely instead of cherry-picking and evaluating carefully each addition.
- SQS handles the whole retry mechanism.
- Adding a new dissector is as easy as plugging a new Lambda function to the Amazon Simple Notification Service (SNS) topic.
- Everything is decoupled, it is easy to update one part without touching the rest.
- Each new release of libyara increases its performance and it is directly correlated to the execution duration’s average.
- Everything is instrumented, we learned to love the AWS Monitoring Console.
Performance Stats 🔗
For those who like numbers, here is a screenshot of the activity of the last 6 months:

On average:
- A batch of samples is scanned in less than 30s
- There are always 45 Lambda functions running at any given time
- 97% of the executions are successful
- We send 150 samples per minute (before deduplication) to dissectors
CobaltStrike 🔗
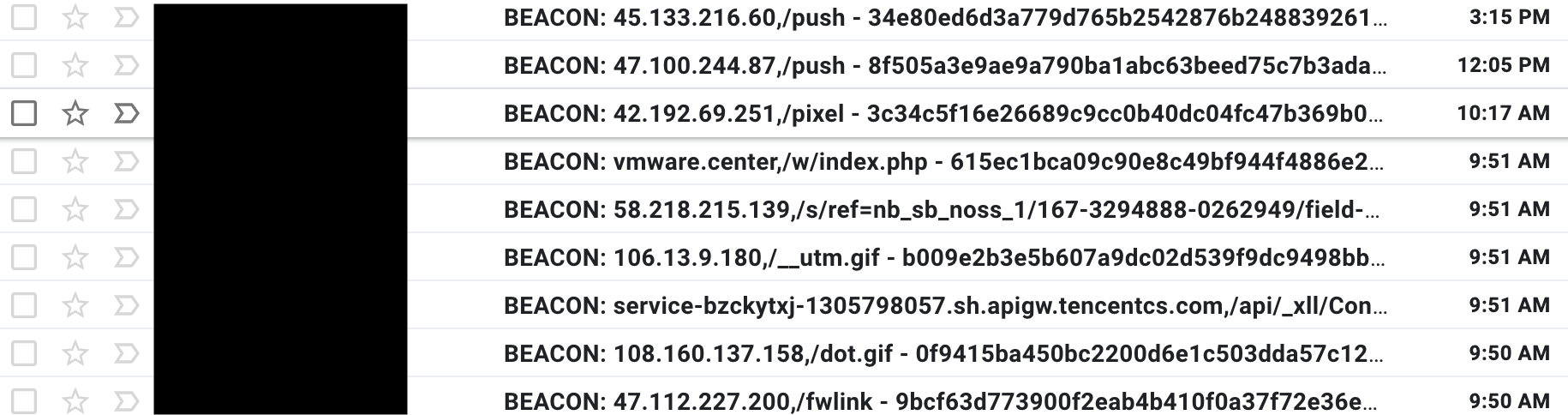
We are using CobaltStrikeParser from Sentinel One to parse the beacons, then we are sending the JSON output to our Splunk instance.
There are two uses of this data:
- Threat Hunting: tracking some Threat Actors
- Proactive protection: adding proactively the IOC to a watchlist in our scope
For Threat Hunting perspectives, we implement alerting for things like:
- Specific watermark identifiers
- Patterns in the C2 domain
- Non-standard values for some fields
- Use of some options or specific malleable profile
Regarding proactive Defense, there is currently no automatic pipeline to push the IOC into a WatchList/DenyList for one reason: it is not uncommon to see trolling BEACONs using legitimate and “assumed safe” domains. To mitigate that, we plan to have a kind of Slack/Mattermost bot that will make us approve each entry seamlessly.